In the fast-evolving field of artificial intelligence, a new frontier is emerging at the intersection of computer vision and natural language processing: Vision Language Models (VLMs). These models are not just transforming how machines interpret images or understand text—they’re enabling intelligent systems to do both simultaneously.
Whether it’s describing an image, answering questions about visual content, or generating new media based on prompts, VLMs are redefining the capabilities of AI across industries. This comprehensive guide walks you through what VLMs are, how they work, notable models, and the key technologies that make them possible.
What Are Vision Language Models (VLMs)?
Vision Language Models (VLMs) are AI systems designed to process and understand both visual inputs (like images or videos) and textual inputs (like questions, captions, or descriptions). They excel at connecting what is seen with what is said, making them ideal for tasks such as:
- Image captioning
- Visual question answering (VQA)
- Object detection with context
- Scene segmentation
- Text-to-image or image-to-text generation
Unlike earlier AI systems that focused exclusively on either vision or language, VLMs create a shared semantic space that bridges both modalities. It allows for deeper, more contextual interpretations—something traditional models struggled with.
Why Are VLMs Important?
The core strength of VLMs lies in their cross-modal reasoning. For instance, imagine showing a model a picture of a cat lying on a windowsill and then asking, “Is the cat awake?” A traditional vision model might recognize the cat, but a VLM can analyze its posture, eye position, and surrounding clues—then interpret and answer in natural language.
This combined intelligence enables real-world applications like smart assistants, AI-driven content generation, medical imaging analysis, and autonomous systems that need to both “see” and “communicate.”
Key Capabilities of Vision Language Models
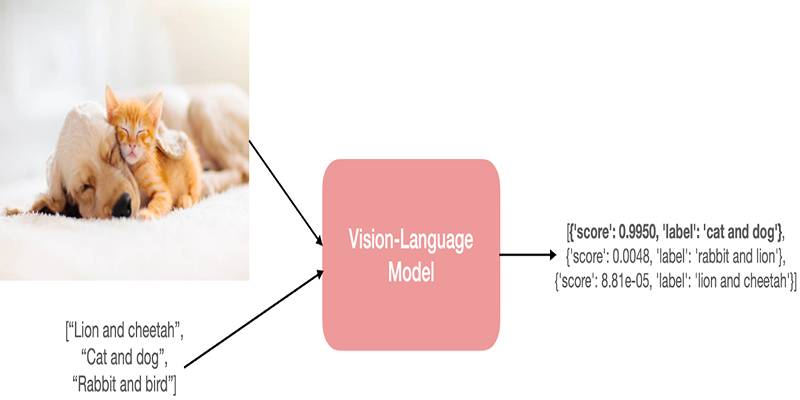
Vision Language Models (VLMs) are revolutionizing the way AI systems interpret and respond to the world by merging visual perception with linguistic intelligence. Below are the core functionalities that make VLMs uniquely powerful and versatile in today’s multimodal landscape:
Vision and Language Integration
VLMs understand the relationships between visual elements and textual data. It empowers them to generate coherent captions, match descriptions to images, and perform search tasks with high accuracy.
Object Detection and Contextual Recognition
Beyond detecting objects, VLMs identify relationships. They can differentiate between “a cat on a couch” and “a cat under a table,” adding a layer of semantic understanding to visual recognition.
Image Segmentation
VLMs divide images into meaningful regions and can describe each segment in text, going far beyond simple labeling. It makes them powerful for detailed image analysis.
Visual Question Answering (VQA)
In this task, the model answers natural language questions based on an image. For example, it might be asked: “How many people are sitting on the bench?” The VLM must analyze the image, understand the question, and reason to provide an accurate answer.
Embeddings for Cross-Modal Search
VLMs encode both images and text into a shared vector space. It allows users to perform text-to-image or image-to-text retrieval, making these models ideal for intelligent search applications.
Notable Vision Language Models
Here are some of the most impactful VLMs pushing boundaries in research and real-world applications:
CLIP (Contrastive Language–Image Pretraining)
Developed by OpenAI, CLIP aligns images and text through contrastive learning. It’s known for its zero-shot learning capabilities—handling classification, captioning, and retrieval tasks without needing task-specific training.
Florence
Florence is a scalable and efficient model designed for large-scale visual and textual tasks. It performs exceptionally well in image recognition, captioning, and multimodal understanding.
LLaVA (Large Language and Vision Assistant)
LLaVA combines large language models with image encoders to power interactive AI systems that can interpret images, engage in visual dialogue, and generate detailed descriptions.
LaMDA (Language Model for Dialogue Applications)
While initially built for conversational tasks, LaMDA becomes a potent VLM when combined with visual inputs. It supports tasks like image-guided dialogue and reasoning.
SigLip (Siamese Generalized Language Image Pretraining)
SigLip is Google's evolution of contrastive learning for vision-language tasks. It uses Siamese networks for improved zero-shot classification, retrieval, and tagging—delivering both speed and accuracy.
Types and Families of VLMs
Vision Language Models can be categorized based on their learning approaches. Each family contributes uniquely to how these models interpret and align vision with language.
Pre-Trained Models
These are trained on massive datasets of paired image and text samples. Once pre-trained, they can be fine-tuned for various downstream tasks using smaller, domain-specific datasets. This flexibility allows for rapid adaptation to new applications without retraining from scratch.
Masked Models
These models use masking techniques—hiding parts of the input image or text during training. The model learns to predict the missing components, which encourages deeper contextual understanding. This strategy is particularly effective for tasks requiring detailed comprehension.
Generative Models
Generative VLMs can produce new outputs, such as generating captions for images or creating images from textual descriptions. They rely on learned representations to synthesize coherent and relevant content, making them highly useful in creative and narrative-driven domains.
Training Vision Language Models

Training Vision Language Models is a multi-step process involving various techniques to improve their cross-modal understanding:
- Data Collection: Massive, paired image-text datasets are curated to train on diverse inputs.
- Pretraining: Models learn the basic alignment of vision and language using methods like contrastive learning or masked prediction.
- Fine-Tuning: They are then customized for specific tasks or domains.
- Generative/Contrastive Learning: Depending on the family, models learn to either produce new content or improve mapping accuracy between modalities.
Conclusion
Vision Language Models are redefining how machines perceive and communicate. By merging the ability to see and understand, VLMs are powering a new generation of intelligent systems that interact with the world in more human-like ways.
From CLIP to PaLiGemma, each model marks a step forward in multimodal AI. Whether it’s enabling smart search, powering creative tools, or enhancing accessibility, VLMs are at the heart of AI’s most exciting breakthroughs.